From manufacturing to marketing, finance, healthcare, or education, generative AI models are revolutionizing the way we work and live. Composing emails, answering questions, writing content, coding, generating images, or even recognizing speech now is at your fingertips.
Thanks to the significant productivity improvement, many companies are seeking to integrate these models into their systems to reduce operational costs and enhance overall success.
However, not every AI integration guarantees benefits for companies. You have to make a wise choice of generative AI models, depending on your domain and resources.
In this article, we’ll walk you through three types of generative AI models that hold the potential to enhance company capabilities: text generation, code generation, and software development.
Before digging into the detail, let us compare the effectiveness of open-source models and commercial models.
Open-source Models and Commercial Models
The impact of AI models is optimized only if we carefully choose suitable models. This involves selecting the relevant model types and sizes that align with each company’s unique demands.
As a matter of fact, when tackling a specific task, there’re two sources of AI models to choose from: open-source and commercial ones. Frankly, you must be aware of disparities in quality between these two groups.
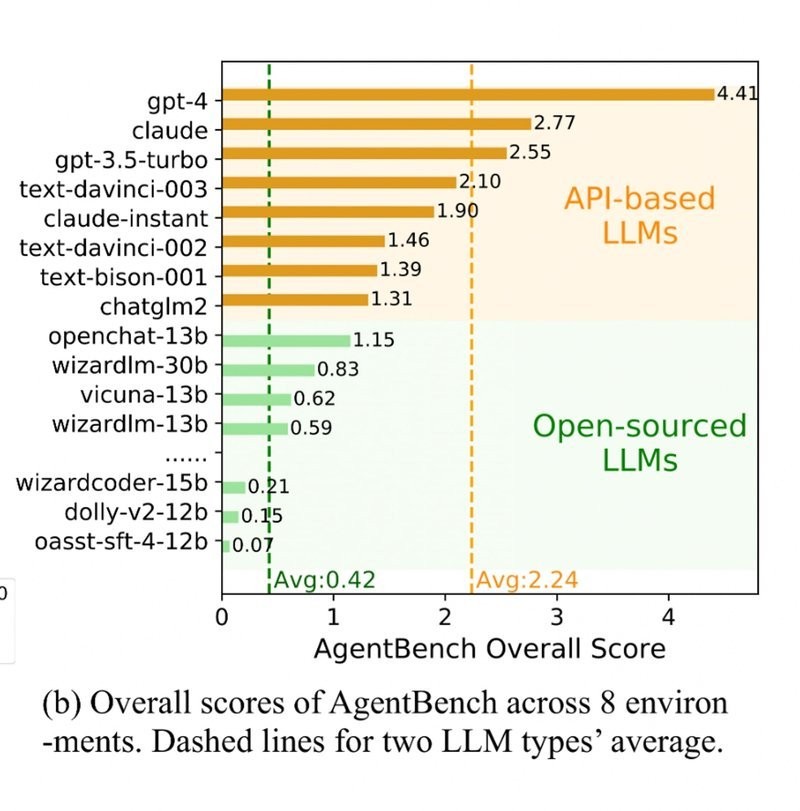
From the graph, we can see that commercial models such as GPT-4, Claude, and GPT-3.5-turbo generally exhibit higher agent benchmark overall scores than free models like Openchat-13B, Wizardlm-30B, and Vicuna-13B. This’s because commercial models are trained on larger and higher-quality datasets. Meanwhile, free models are typically trained on smaller datasets with limited training budgets.
Before deciding the type of model source for your organization, consider the trade-offs between using commercial and open-source models.
Firstly, you need to weigh the API fees for utilizing commercial models. They’re often based on the total number of tokens and images returned by the models in response to your requests. In contrast, open-sourced models are readily available for downloading and inferencing on platforms like Huggingface.
Additionally, despite the higher performance of commercial models, there’s a potential risk of privacy and confidentiality with your dataset when sending it to API services. This raises concerns about inadvertently using personal data to augment the training dataset. Therefore, we recommend fine-tuning the open-sourced models to align with the specific demands of your enterprise.
Text Generation Tools
Most Large Language Models (LLMs) have demonstrated high potential for effectively addressing various text generation tasks. These activities include email summarization, chatbot interactions, and marketing content creation.
There are two different paths you can take to find out which models best suit your organization’s demands. Firstly, compose a list of models and personally test them to arrive at your own conclusions. Another way is searching for some LLM leaderboards that provide benchmarking results of model capabilities.
The former method is not subjective due to small, curated samples. Thus, it’s more comprehensive and insightful if you have a truthful evaluation of LLM models based on the widespread leaderboards.
Fortunately, LMSYS, an open research organization founded by students and faculty from UC Berkeley in collaboration with UCSD and CMU, provides a FastChat-based Chatbot Arena leaderboard to evaluate the model’s general capability. The evaluation scope includes summarization, marketing content, and chatbot.
This dataset gathered approximately 13K anonymous votes from the community on the voting system as in Table 1:
From the rankings and data collected from this leaderboard update, we have a few interesting findings.
Gaps Between Proprietary and Open-source Models
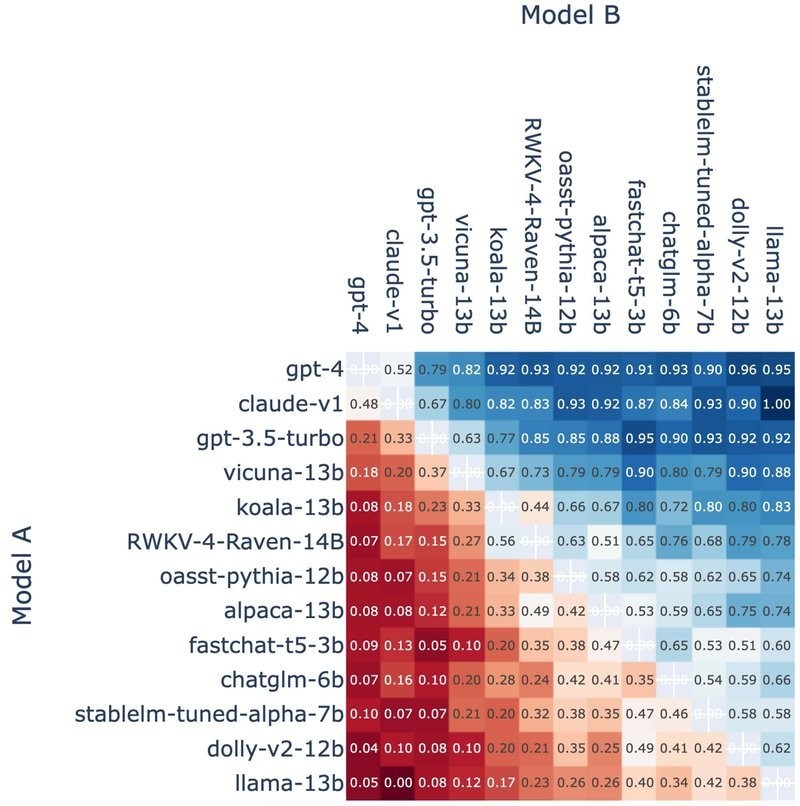
We observe a substantial gap between the three proprietary models and all other open-source models.
In particular, GPT-4 is leading the board, achieving an Elo score of 1274. It is almost 200 scores higher than the best open-source alternative on this board Vicuna-13B.
After dropping ties, GPT-4 wins 82% of the matches when it’s against Vicuna-13B, and it even wins 79% of the matches when it is against its previous generation GPT-3.5-turbo.
Please note that these open-source models on the leaderboard generally have fewer parameters, in the range of 3B – 14B, than proprietary models. However, the improvement does not just originate from increasing the model size.
In fact, the recent advancements in LLMs tweet and data correctness have permitted significant improvements in performance with smaller models. For instance, Google’s latest PaLM 2 is more prominent than the precedented PaLM 2 even though it has a smaller size. This is achieved by training the model on curated datasets.
Comparing Proprietary Models
Based on the collected voting results, Anthropic’s Claude model is preferred by the users over its opponent, GPT-3.5-turbo. Still, Claude is highly competitive even when competing against the most powerful model – OpenAI’s GPT-4.
Looking at the win rate plots in the figure 2 below, among the 66 non-tied matches, Claude indeed wins over GPT-4 in 32 (48%) matches.
Code Generation Systems
Code generation stands as a vital function that aids programmers in writing code according to their provided specifications. This capability holds great significance in minimizing workload and expediting the coding endeavors of developers.
The code recommendations furnished by language models exhibit exceptional accuracy. The output quality is not less than the experienced developers. Beyond this, these models can elucidate the code and craft documentation for any given function through an analysis of the function’s content.
There is a load of models that show amazing ability in code generation, which include commercial products and open-sourced models.
Indeed, commercial systems maintain a prominent presence in the realm of open-source models. Nevertheless, the cost associated with utilizing these commercial products can be steep, and their usage does not guarantee the confidentiality of your code. This factor contributes to the continued preference for open-source large language models.
An authentic and dependable evaluation of code generation can be carried out through human assessment, and the following outlines such an evaluation process:
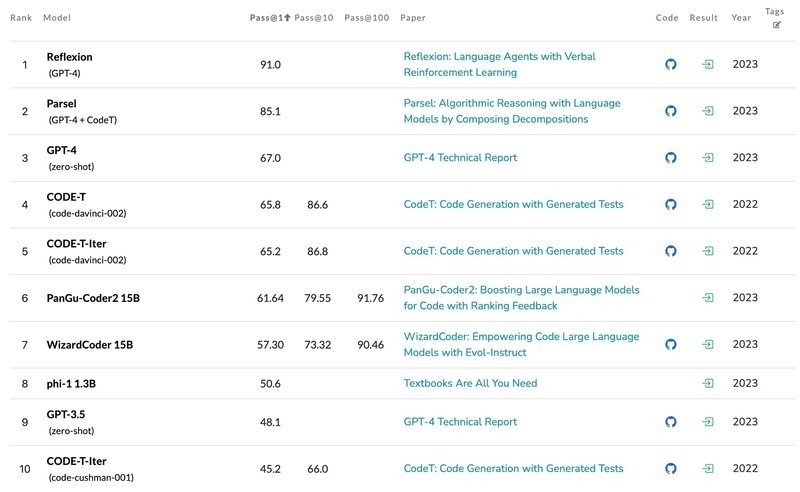
The table demonstrates that GPT-4 and CODE-T models have the highest performance.
The GPT-4 reflection reaches the 1st position with 91.0% Pass@1 score. The 2nd one is Parsel, an ensemble of GPT-4 + CodeT models with 85.1% Pass@1 score. There is a huge gap between the two best models with the following ones like CODE-T (code-davinci-002) with 65.8% Pass@1, and GPT-3.5 with 48.1% Pass@1.
All of the aforementioned models are used for commercial purposes. Frankly, many open-sourced models show that they have a stunning capability at generating code. For instance, Salesforce AI Research officially releases the CodeGen1 and CodeGen2 models (350M, 1B, 3B, 7B16B) for program synthesis.
In addition, StarCoder and StarCoderBase are Large Language Models for Code (Code LLMs) trained on permissively licensed data from GitHub. They support 80+ programming languages, Git commits, GitHub issues, and Jupyter notebooks.
Similar to LLaMA, we trained a ~15B parameter model for 1 trillion tokens. We fine-tuned StarCoderBase model for 35B Python tokens, resulting in a new model that we call StarCoder.
The evaluation shows that StarCoderBase outperforms existing open Code LLMs on popular programming benchmarks and matches or surpasses closed models such as code-cushman-001 from OpenAI. This is the original Codex model that powered early versions of GitHub Copilot.
With a context length of over 8,000 tokens, the StarCoder models can process more input than any other open LLM, enabling a wide range of interesting applications.
Software Development Systems
Software project management holds a crucial role within many IT companies. Each software project involved many positions, spanning Project Management, Solution Architecture, Software Engineering, Business Analysis, and Quality Assurance.
One approach requires automating various roles within a software project’s development pipeline. In specific, Multi-Agent models possess the capacity to oversee and orchestrate the entire software product development process autonomously, without human intervention.
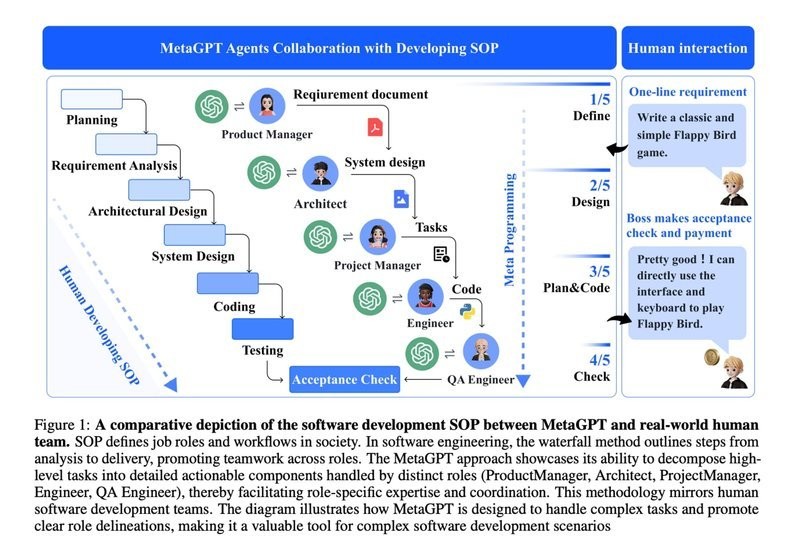
For instance, MetaGPT is a new meta-programming framework for multi-agent collaborative systems. It is designed to organize and manage IT projects, as well as other complex tasks that require coordination between multiple agents.
MetaGPT works by first creating a hierarchical model of the task to be performed. This model is then used to generate a set of instructions for the agents. The instructions are dynamically generated, so they can be tailored to the specific needs of the task.
MetaGPT also includes a number of features to help the agents coordinate their activities. They are a communication protocol, a conflict resolution mechanism, and a reward system.
The authors of MetaGPT evaluated their framework on a number of different tasks, including software development, project management, and disaster response. They found that MetaGPT was able to outperform traditional approaches to multi-agent coordination.
Here are some of the key functtionalities of MetaGPT:
Meta-programming: Use meta-programming to generate instructions for the agents. This allows adapting the framework to new tasks without manual programming.
Hierarchical task model: Use a hierarchical task model to represent the task. This enalbes the framework to decompose complex tasks into smaller, more manageable subtasks.
Dynamic instructions: Generate instructions dynamically, so they can be tailored to the specific needs of the task.
Communication protocol: Include a communication protocol to allow the agents to communicate with each other.
Conflict resolution mechanism: Offer a conflict resolution mechanism to resolve disagreements between the agents.
Reward system: Provide a reward system to encourage the agents to cooperate and complete the task successfully.
Final Thoughts
Despite the considerable progress in Large Language Models (LLMs) field, certain challenges such as hallucination, privacy concerns, bias, and ethical risks still persist.
Nevertheless, AI has taken a significant stride forward in creating a new generation of LLMs that exhibit increased intelligence and wisdom in catering to a multitude of tasks. Employing localized LLMs has also become apparent, particularly due to their capability to uphold privacy and cater to diverse company requirements.
The critical aspect lies in the meticulous selection of appropriate open-source models to align with specific demands, thereby optimizing the efficiency of the model.
We’ve walked your way up to models that will enhance your understanding of employing LLMs, especially within the realm of the IT industry.
Trinh Nguyen
I'm Trinh Nguyen, a passionate content writer at Neurond, a leading AI company in Vietnam. Fueled by a love of storytelling and technology, I craft engaging articles that demystify the world of AI and Data. With a keen eye for detail and a knack for SEO, I ensure my content is both informative and discoverable. When I'm not immersed in the latest AI trends, you can find me exploring new hobbies or binge-watching sci-fi
Content Map What Is AI Readiness? 4 Key Components of AI Readiness Assessment 5 Steps to Achieve AI Readiness Overcoming Common AI Readiness Challenges Ready to Take the Next Step Toward AI Readiness? It’s estimated that companies adopting artificial intelligence saw a 3.5X return on investment (ROI) for every dollar spent. But is your organization […]