Reinforcement Learning based Recommendation System
Development Process
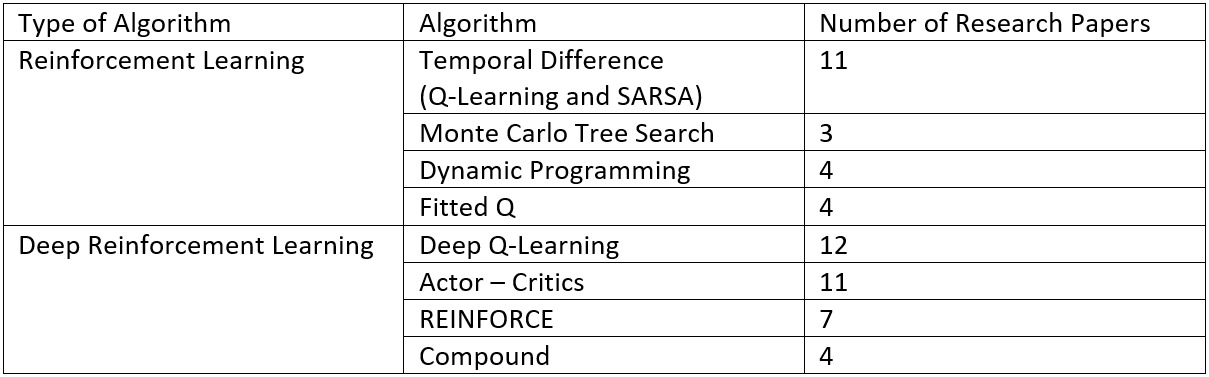
As we mentioned above, in the nature of Reinforcement Learning(RL), the agents try to maximize the reward when interacting with the environment. This is similar to the problem of Recommendation System that the Recommendation System algorithm tries to recommend the best items to the users and maximize the satisfaction of users. In a big picture, we can consider the Recommendation System system as an agent, and anything outside the agent as environment. But in the real-life, because the data is huge result in the enormous faction and state spaces, some RL algorithms cannot carry on. Beside some appropriate RL algorithms for Recommendation System, the trend of Deep RL algorithm is becoming emerging and considered strictly in some relevant aspects. The table below from the survey shows us the algorithms used in many research papers.
Summarize from “Reinforcement Learning based Recommender Systems: A Survey” — (arxiv.org)
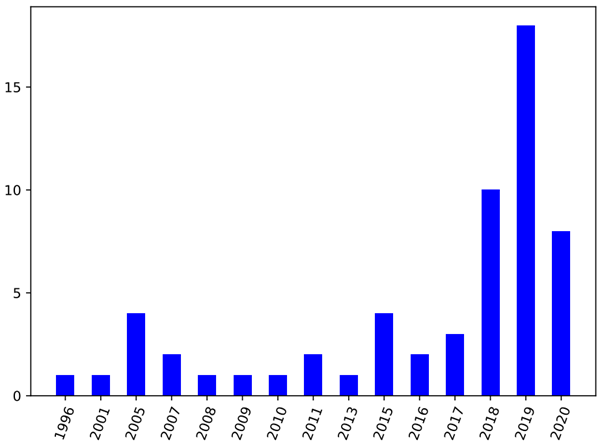
In the bar chart below, RL have been applied in Recommendation System from 1996 till 2020. However, before 2018, there are not much research papers about this topic in those year, which only stay less than 5. This is maybe because the RL have been developed and tested so just small number of researches pay attention to this topic. Besides, we also lacked of huge datasets, online testing environment and unified/standard evaluation method. From 2018 till now, there is a burst in researching that topic with many algorithms from both RL and Deep Reinforcement Learning(DRL). From the result of those research papers, we have some dominant algorithms with frequently used datasets to train and metrics to evaluate Recommendation System. Those will be explained in next part.
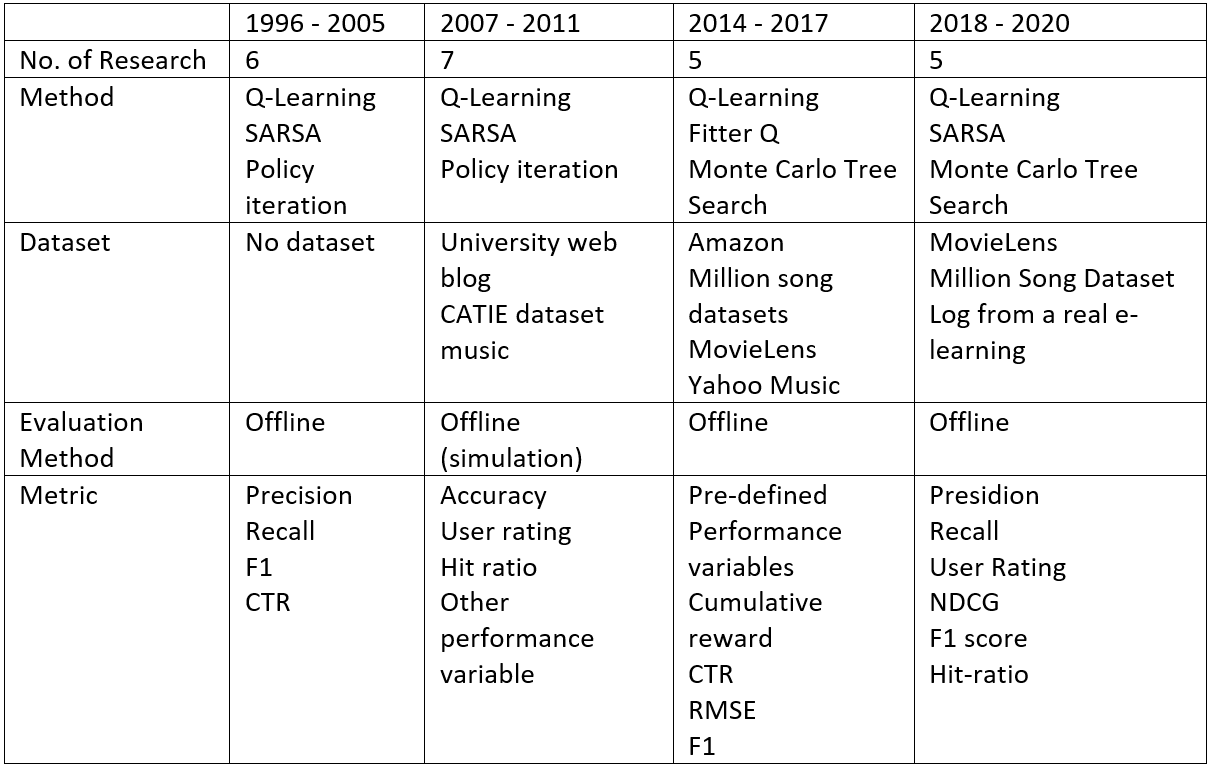
From the table below, the reinforcement learning algorithms has been applied in RS in the early days. Beginning with temporal difference method (Q-Learning/SARSA) and dynamic programming (Policy iteration), researchers have less change in method they used to conduct the research. From it till now, although they are developing many new algorithms, temporal difference with Q-Learning and SARSA still is a popular method due to its advantages presented below. Moreover, more datasets — especially real-life dataset such as Amazon and MovieLens — are trustworthy to used due to their structured data and metadata providing more information for each items/users. However, most evaluation procedures are offline by building a simulation environment and using some metrics that have changes through each research papers. Then we have a list of popular metrics:
Precision: ratio of true positive over total positive
Recall: ratio of true positive over real positive (include true positives and false negative)
F1 Score: Harmonic mean of Precision and Recall
NDCG: Normalized Discounted Cumulative Gain, a measure of raking quality of recommendation system.
CTR: Click through rate, which is the ratio of clicks by user on a specific detail of recommendation over the total user who see the recommendation.
RMSE: Root Mean Square Error
Summarize from “Reinforcement Learning based Recommender Systems: A Survey” — (arxiv.org)
Each method has its own algorithms with those advantage and disadvantage.
Dynamic Programming (DP): Among the tabular methods, DP methods are not popular and impractical due to their huge computational expense and the need to understand widely about the environment. Although this algorithm has the large number of states, it is often infeasible when conducting even one iteration of policy or value iteration methods.
Monte Carlo (MC): This tabular method does not require more knowledge of the environment, just only need sampled experience such as interactions with the environment. However, MC methods still have some limitations. They do not bootstrap and they update value function only after completing episode, so their convergence is slow. An upgrade of MC, which called MCTS, is used enhance the efficiency of MC.
Temporal Difference: Those methods have been very popular in most of development period of RS because they are simple, model-free and need minimal amount of computation and can be expressed by a single equation. The preventative of those method are Q-Learning and SARSA.
Fitted-Q: a flexible framework that can fit any approximation architecture to Q-function but its limitation is high computational and memory overhead.
Deep Reinforcement Learning Algorithms
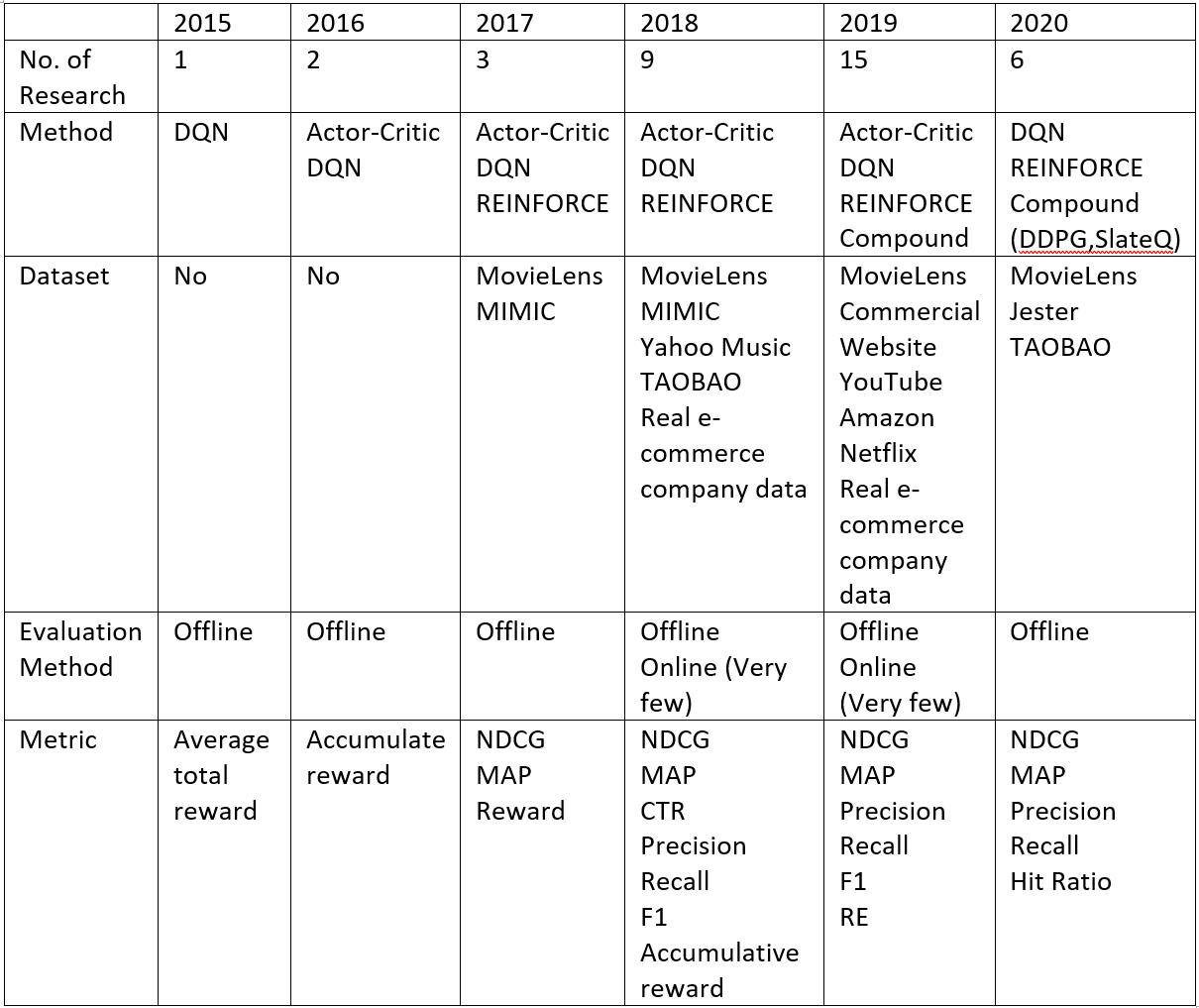
Coming later than the original RS algorithms, but Deep Reinforcement Learning Methods has proved to the researchers about their feasibility and efficiency, but still having small drawbacks for each method. In the table below, in 6 years, there are more research has been conducted which dominant methods are Deep Q-Learning and Actor — Critic, but the trending in 2020 till now are combining two or more methods whose advantages can support to solve the drawbacks of other methods. The datasets also become more diverse which tend to use some popular datasets in entertainment and e-commerce. Although evaluation procedures still is in offline, but some researches have built up a online evaluation having good initial results. The metrics to evaluate the RS with DRL also still the same as ones of RL above such as precision, recall, NDCG, F1, hit-ratio… We have some short description about those methods.
Summarize from “Reinforcement Learning based Recommender Systems: A Survey” — (arxiv.org)
DQN: This method modified the original Q-learning algorithm in three aspects to improve the stability. Firstly, it uses experience replay and a method keeping agent’s experiences over various time steps in a replay memory, then uses them to update weights in the training phase. Secondly, to reduce the complexity in updating weights, current updated weights are kept fixed and fed into a duplicate network whose outputs are used as the Q-learning targets. Third, to limit the scale of error derivatives, the reward function is simplified. However, DQN has three problems. Firstly, it overestimates action values in some certain cases, making learning inefficient and lead to sub-optimal policies. Secondly, DQN select experiences randomly uniformly to replay without considering its significant, making the learning process slow and inefficient. Third, DQN cannot handle continuous, which has computational expense and high infeasibility.
REINFORCE: A Monte-Carlo, stochastic gradient method which directly updates the policy weights. However, its problems are its high variance and slow learning result from the nature of MC when it takes samples. In current, there are some different technique which have been developed to deal with high variance problem.
Actor — Critic: This algorithm uses a critic to criticize the policy generated by actor by computing the value of the state-action pair given by the actor and proving feedback on the selected action, which deals with problems of REINFORCE through reducing variance and accelerates learning.
Compound: The combination of many DRL algorithm is considered and developed by many researchers because they can take advantage of each method and reduce or their drawbacks. One example we can tell is DDPG, an algorithm combining DQN and DGP (both are DRL methods), have proved its enhancement over single method and potential efficiency. In future, many researchers will consider more compound methods to find the best combination satisfying some continuously updated criteria.
Obstacles and Improvement in Future
Single Items to multiple items recommendation: RL algorithms have been developed to select one action from many different actions around. But in the RS field, the system has tendency to generate a list of items. In many researches, the vast number of reviewed research paper consider the problem of single item recommendation. In recent years, the researching trending is about recommending a list of items. However, the researchers have to face with the problem of huge combinatorics action space, because when the action space is larger, there are more demand on exploration, generalization and optimization.
Spotify recommends more type of mix-tape/mood/music content with many songs for users
Architecture of algorithm: At the moment, most of existing RS using DRL method have been developed and tested in many environments. However, those methods base on physics processes, not sophisticate and dynamic nature of users. So that we should have more creative method to deal with that problem. Besides having some RL algorithms popular among RS, the combination of Deep Learning and RL (compound) is becoming a valuable research direction for the future trending algorithm.
Although still having been developed and tested, but Deep Reinforcement Learning will be a dominant method for Recommendation Systems in futures
Explainable recommendation: The ability of an RS not only to provide a recommendation for user but also to explain the reason why the system recommend those items. Explanation about recommendation could improve user experience, boost the system’s trust and help RS make better/accurate decisions. Over more, this criterion help developer to track the operation of RS, then find and fix the bug or have changes in algorithm structure in need. However, this criterion still do not receive enough attentions in spite of its potential contribution in enhancing quality of RL. So that, more researchers should focus on this aspect in future.
Researchers still need to agree on a common evaluation standard on some aspects such as efficiency or performance
Improving evaluation method for RL in Recommendation System:
In the RL process, the agent interacts with the environment to learn what to do, which have similarity with online evaluation that RS generates the recommendations and receives the user feedback in real-time. However, most of the reviewed research papers just use offline evaluation because conducting online evaluation costs a huge price and deploying RL in Recommendation System is very risky in real businesses. On the other hand, many researchers develop the simulations for offline evaluation with the available datasets such as MovieLens, Amazon, any real business database, etc. But most of user models in those simulations are too simple and cannot reflect the behaviors of real users. Although there are some methods to simulate user’s behaviors, we have to develop a powerful simulator and an evaluation framework for RL in Recommender System in the future.
I'm Trinh Nguyen, a passionate content writer at Neurond, a leading AI company in Vietnam. Fueled by a love of storytelling and technology, I craft engaging articles that demystify the world of AI and Data. With a keen eye for detail and a knack for SEO, I ensure my content is both informative and discoverable. When I'm not immersed in the latest AI trends, you can find me exploring new hobbies or binge-watching sci-fi
Content Map What Is AI Readiness? 4 Key Components of AI Readiness Assessment 5 Steps to Achieve AI Readiness Overcoming Common AI Readiness Challenges Ready to Take the Next Step Toward AI Readiness? It’s estimated that companies adopting artificial intelligence saw a 3.5X return on investment (ROI) for every dollar spent. But is your organization […]