Vision language models are an exciting application of multimodal AI that can understand visual and textual information simultaneously. They’ve recently received a lot of attention from the public since most AI models focus on processing image or text inputs only. Vision language models can perform tasks involving both modalities.
There are multiple vision-language models available. Still, recognizing their capabilities so you can choose the right model for your project has never been a simple task.
Fortunately, our AI engineers have spent time researching and training popular VLMs. The result will give you a better understanding of vision language models (VLMs) and showcase how they integrate visual and text inputs to enhance AI capabilities and evaluation strategies.
Let’s jump into the details.
What Is a Vision Language Model?
As mentioned, vision language models are defined as multimodal AI models that can learn from images and text content. In other words, they take image and text inputs, then generate text outputs to serve visual question answering, image captioning, image recognition, document understanding duties, and more.
The image inputs, consisting of detected or segmented objects and the spatial layout of the image, will be mapped with the text embeddings. For instance, if an image contains a dog playing in a park, the model will identify and segment the dog and the park as distinct objects, along with their spatial arrangement. These visual elements are then mapped to corresponding text embeddings, allowing the model to generate a descriptive sentence like “A dog is playing in the park.” This mapping process enables the Vision-Language Model to understand and articulate the relationship between visual components and their textual representations.
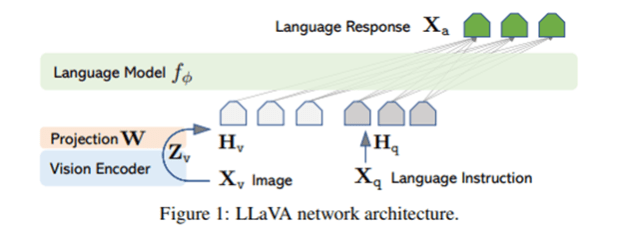
Architecture of Visual Language
A vision-language model typically consists of three key elements: an image encoder, a text encoder, and a strategy to fuse information from the two encoders. The architecture of a visual language model follows a clear process: visual input is encoded using a vision encoder, which is then connected to a trainable W matrix. This matrix projects the visual data to match the dimensionality of the base LLM. Subsequently, the encoded visual input is concatenated with text input, allowing the model to generate coherent responses through the LLM. This entire pipeline is trained using multimodal data, often generated by models like GPT-4 in the case of LLaVA.
Popular Vision Language Models
We’ve picked the most well-known vision language models for training. The following are some of the prominent players and their contributions to the Vision Language Model era, which are revolutionizing the way we interact with and understand visual and textual content.
LLaVA: This model represents an end-to-end trained large multimodal model. It comes with multiple versions and is built on various base LLMs, including Vicuna-LLaMA 2, LLaMA 3, Mistral, and Hermes-Yi. The latest version, LLaVA 1.6, currently lacks finetuning code.
Qwen-VL: Qwen-VL is a set of large-scale vision-language models (LVLMs). Based on the Qwen architecture, this model uniquely accepts bounding box inputs and outputs, enhancing its capability to process visual information.
Yi-VL-34B: Yi Vision Language, or Yi-LV, is an open-source multimodal version of the Yi Large Language Model (LLM) series. Grounded in the Yi architecture, Yi-LV offers distinct multimodal functionalities and exceptional performance. It ranks first among all existing open-source models in the latest benchmarks, including MMMU in English and CMMMU in Chinese. Yi-VL-34B is the world’s first open-source 34B vision language model.
CogVLM: Built on LLaMA 2 with fine-tuning for enhanced performance, CogVLM can handle higher image quality and resolution compared to its peers. CogVLM-17B contains 10 billion visual parameters and 7 billion language parameters, allowing it to understand images and create multi-turn dialogues with a resolution of 490*490.
Phi3-Vision: Offered by Microsoft’s AI, it comes as a lightweight and state-of-the-art open multimodal model. As the first multimodal model in the Phi-3 family, Phi-3 Vision surpasses the capabilities of Phi-3-mini, Phi-3-small, and Phi-3-medium by effortlessly combining language and visual information. Its extensive context length of 128K tokens enables it to handle complex and detailed interactions. This model is pre-trained on an OCR dataset, making it suitable for document understanding tasks.
Pixtral 12B: Natively designed to process both images and text, this model is trained on interleaved image and text data. It demonstrates strong performance on a variety of multimodal tasks, including effectively following instructions. Pixtral 12B excels in one-shot learning scenarios, showcasing an impressive average CER of 0.166 on the test set with the seen formats.
Molmo-7B-D: This model is based on Qwen 2.5-Vision 7B and uses OpenAI CLIP as a vision backbone. It receives high accolades from online reports with its zero-shot capabilities.
Vision Language Models Training
Pretraining
We decided to use invoice document datasets to test the performance of the above models. There are numerous reasons for this. Invoices come in diverse formats and layouts, with different fonts, font sizes, and text orientations. This diversity challenges models to adapt to different visual structures. Real-world invoices often contain noise like watermarks, stamps, or handwritten annotations, which can interfere with accurate text extraction and understanding. Moreover, their multimodal nature, combining visual elements (images, logos) with textual content (product descriptions, quantities, prices, etc.) makes them well-suited to be processed in vision-language models. Plus, invoices prove common business operations, making them a practical choice for evaluating models intended for real-world applications like automated data entry, expense management, and financial analysis.
We conducted testing on FATURA dataset, an invoice document understanding dataset consisting of 10,000 invoices with 50 distinct layouts.
We created two distinct test sets to evaluate the ability of models: the seen and unseen formats.
Seen format: The models are tested on layouts that they have already included during training. This test set assesses the model’s ability to recognize and process familiar layouts accurately. The model’s performance will indicate how well it has learned the patterns and features of the training data.
Unseen format: The models are tested on layouts that they have never seen before. This test set evaluates the model’s capability to generalize its knowledge to new layouts. The model’s performance on this set will indicate its ability to adapt to new situations and its robustness to variations in layout.
Using both seen and unseen format test sets enables our researchers to have a comprehensive understanding of models’ capabilities. A model that performs well on both sets is likely to be more robust in real-world applications.
Results
Here are the key metrics from our tests:
Model
Test Format
Average CER (Lower is better)
LayoutLMv2 (OCR baseline)
Unseen format
0.089
LLaVA 1.5
Seen format
0.687
Phi3-Vision (regular text output)
Seen format
0.167
Phi3-Vision (JSON)
Seen format
0.144
Unseen format
0.174
Phi3.5-Vision (JSON)
Seen format
0.245
Unseen format
0.282
Pixtral 12B (one-shot)
Seen format
0.166
Molmo-7B-D
Seen format
N/A (poor)*
Note on Molmo-7B-D results: The full training has led to poor evaluation results, as the model often repeats itself on the test set and struggles to adhere to the training set format.
Key Findings from Finetuning Vision Language Models
Despite the potential of large vision language models, there still remain several challenges. Here are some key findings of our researchers after the model training.
Codebase Consistency: Most codebases adhere to the LLaVA format. However, they are often poorly maintained. Bugs reported on platforms like GitHub frequently go unresolved.
Scarcity of Reports: There is a notable lack of documentation on the use and finetuning of open-source Vision LLMs. As a result, their application is predominantly confined to research and experimental contexts rather than practical, production-level uses.
Hardware requirements: All the tested models (LLaVA 1.5, were able to be finetuned with Low-Rank Adapter (LoRA) using 1x RTX 4090 GPU (24 GB), except Molmo-7B-D, which presented hardware challenges during finetuning, requiring significant VRAM (144GB with 3xA40 for a batch size of 1 in bf16). For Pixtral 12B, due to hardware limitations, we only tested one-shot results and not finetuning.
Finetuning Results: Compared to our OCR baseline using LayoutLMv2, none of the Vision LLMs we tested can match the performance. The best performers are Phi3-Vision with finetuning and Pixtral 12B for one-shot prompting. The one-shot performance of Pixtral 12B is very competitive; however, we couldn’t test its finetuning performance as mentioned.
While finetuning for tasks like OCR and document understanding shows promise, these models are prone to hallucinations and may overlook or miss critical information.
LLaVA 1.5 demonstrated poor performance on test sets, even after convergence. We doubted that this model was not trained extensively on the OCR/document understanding task. The newer model, LLaVA 1.6 was advertised to have much better OCR performance. However, finetuning code for it was not available.
In contrast, Phi3-Vision yielded good results, although it still suffered from missing information in several fields. While hallucination and incorrect OCR outputs are infrequent, the model can sometimes produce endless text outputs. This endless output problem is a common theme for all finetuned models we tested, while it was not a problem with the stock models.
Interestingly, Phi3.5-Vision demonstrated worse performance than its predecessor Phi3-Vision. Molmo-7B-D’s results were also poor considering the good online reports it received.
Final Thoughts
Vision Language Models (VLMs) represent a significant advancement in multimodal AI. These models, capable of processing both visual and textual information, have the potential to revolutionize various industries.
However, our research reveals that while VLMs offer promising capabilities, there are still significant challenges to overcome. While models like Phi3-Vision and Pixtral 12B show potential in tasks like document understanding, they are prone to hallucinations and inaccurate outputs. Additionally, the lack of robust and accessible finetuning methodologies hinders their practical application.
To fully realize the potential of VLMs, further research and development are necessary to address these limitations. This includes improving model accuracy, reducing hallucinations, and developing efficient finetuning techniques. As VLMs continue to evolve, we can anticipate exciting breakthroughs in areas such as automated data extraction, image analysis, and natural language understanding.
I'm Trinh Nguyen, a passionate content writer at Neurond, a leading AI company in Vietnam. Fueled by a love of storytelling and technology, I craft engaging articles that demystify the world of AI and Data. With a keen eye for detail and a knack for SEO, I ensure my content is both informative and discoverable. When I'm not immersed in the latest AI trends, you can find me exploring new hobbies or binge-watching sci-fi
Content Map What Are Vertical AI Agents? Comparing Vertical and Horizontal AI Agents Key Characteristics of Specialized AI Solutions Benefits of Domain-specific AI Applications Industry Specific Benefits of Vertical AI Key Features of Effective Vertical AI Agents Implementing Vertical AI Agents Successfully Challenges and Risks in Adopting Vertical AI Mentioning AI, this term has moved […]